Contents
User Guide¶
Introduction¶
Ikkuna is a framework for supervising the training of your PyTorch models. It is stupidly easy to use. It allows you to code your chosen metric once and then use it from any kind of model. It also comes with a few metrics out of the box.
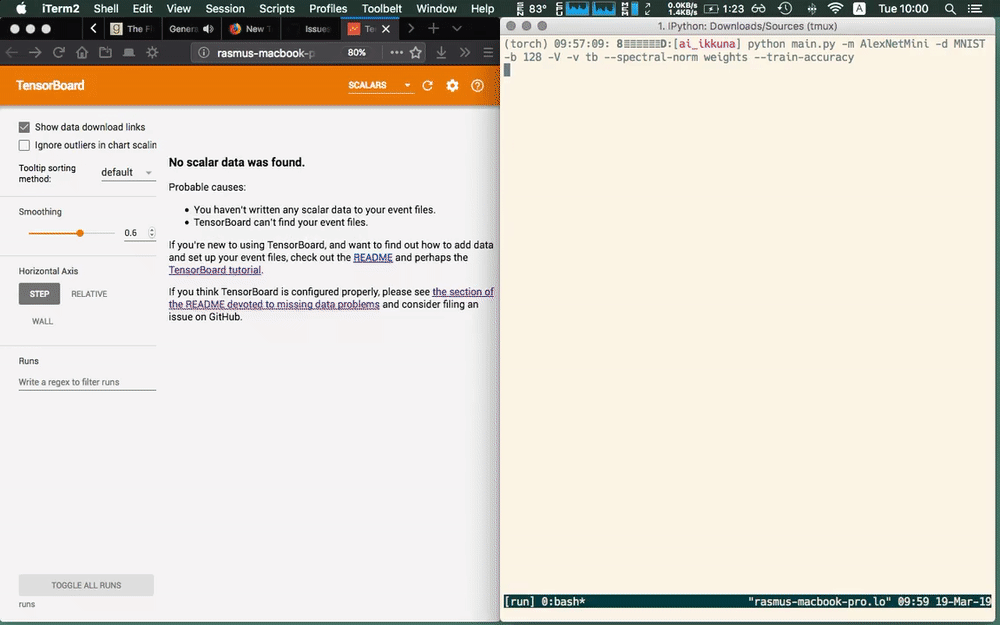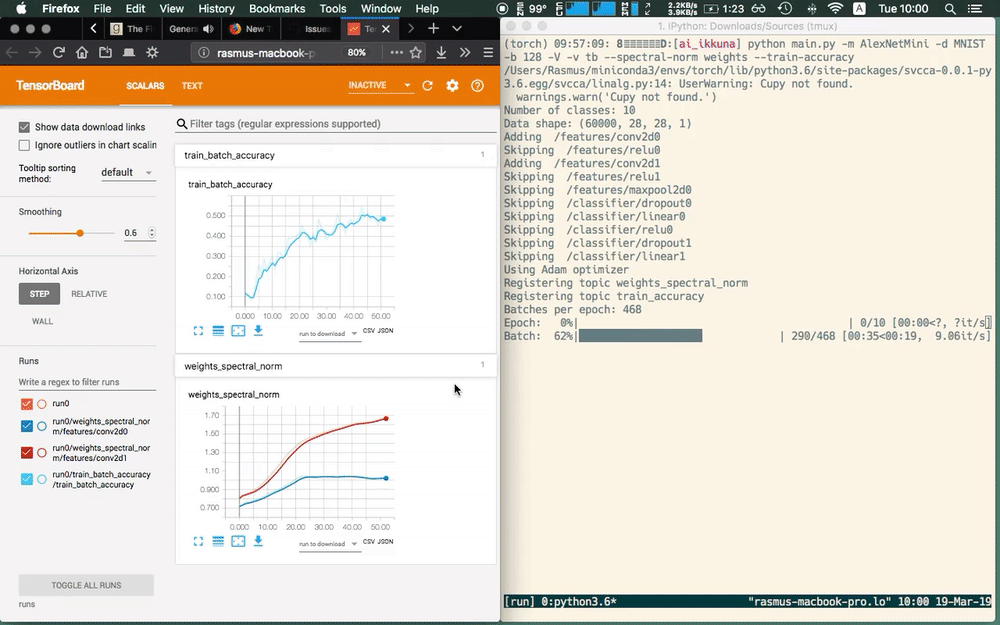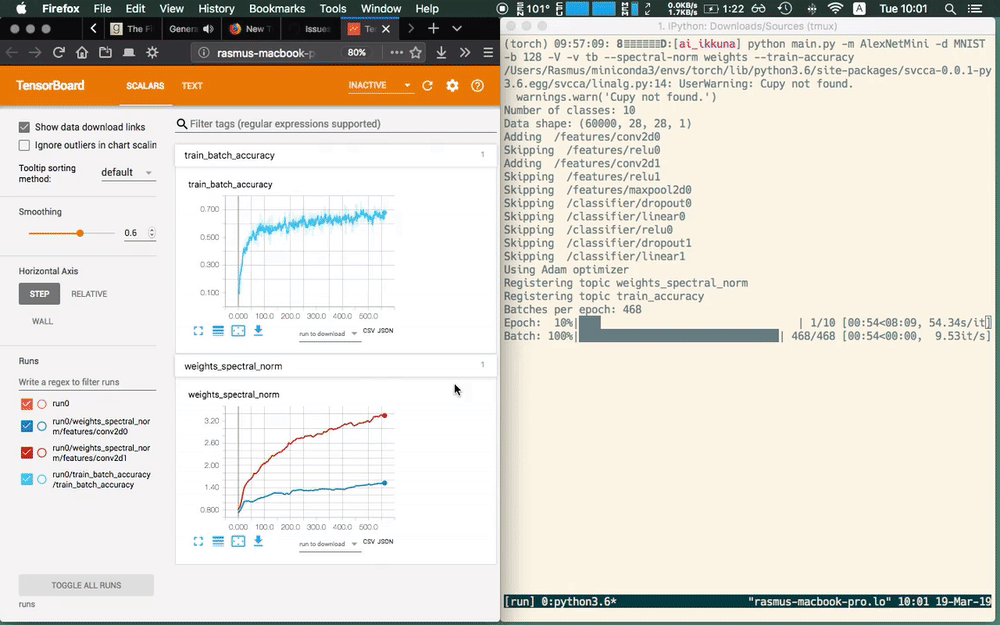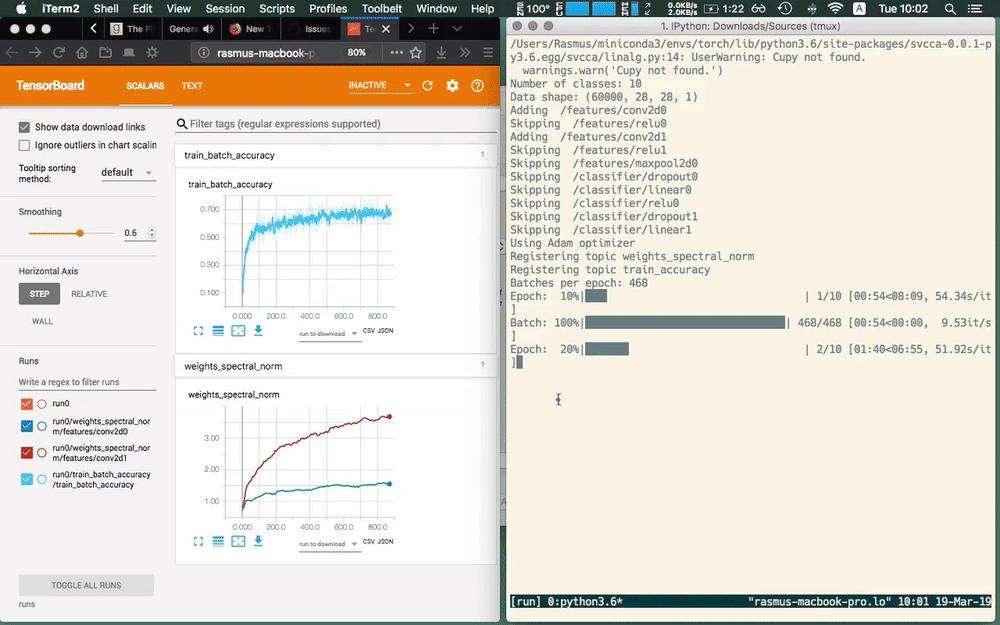
Here we use the main.py script for demoing what ikkuna does.
We let ikkuna plot training accuracy and the spectral norm of the layer
weights without having to care about the specific model. The library
automatically discovers the model structure — it filters for conv layers
here — and adds the metric to it.
The metrics which are ready to use are
- Training Accuracy
- Validation Accuracy
- Training loss
- Variance of gradients, weight updates, etc.
- p-Norm of gradients, weights, etc.
- Ratio between weight updates and weights, or other quantities
- Spectral norm of weights etc
- Histograms
- SVCCA layer saturation metric presented in my master thesis.
Installation¶
Prerequisites¶
This package requires you to have PyTorch 0.5 or newer installed. Unfortunately, the PyPI versions always lag behind, so you may have to compile PyTorch yourself. Don’t worry, it is a straightforward albeit somewhat time-consuming process.
Warning
If you install the torchvision package after installing PyTorch from
source, it will overwrite your PyTorch installation with an older version.
So if you need it, install it from source as well or do it before
installing PyTorch. The issue has been reported here.
Installing the library¶
ikkuna can then be installed with pip
pip install ikkuna
Alternatively, run
pip install git+https://github.com/Peltarion/ai_ikkuna.git#egg=ikkuna
or
git clone git@github.com:themightyoarfish/ikkuna.git
cd ikkuna/
python setup.py install # can use `pip install -e .` as well
to get the bleeding-edge version.
Reporting Issues¶
This project is under development and — by virtue of being a thesis project — probably unstable and bug-ridden. Therefore, expect to encounter issues. For reporting, please use the issue tracker.
Quickstart¶
Using the library is very simple. Assuming you have a PyTorch model given, like this ConvNet
class Net(torch.nn.Module):
'''Reduced AlexNet (basically just a few conv layers with relu and
max-pooling) which attempts to adapt to arbitrary input sizes, provided they are large enough to
survive the strides and conv cutoffs.
Attributes
---------
features : torch.nn.Module
Convolutional module, extracting features from the input
classifier : torch.nn.Module
Classifier with relu and dropout
H_out : int
Output height of the feature detector part
W_out : int
Output width of the feature detector part
'''
def __init__(self, input_shape, num_classes=1000):
super(Net, self).__init__()
# if channel dim not present, add 1
if len(input_shape) == 2:
input_shape.append(1)
H, W, C = input_shape
# couple o' convs, poolings, and relus
self.features = torch.nn.Sequential(
torch.nn.Conv2d(C, 64, kernel_size=5, stride=2, padding=1),
torch.nn.ReLU(inplace=True),
torch.nn.MaxPool2d(kernel_size=3, stride=2),
torch.nn.Conv2d(64, 192, kernel_size=3, padding=2),
torch.nn.ReLU(inplace=True),
torch.nn.MaxPool2d(kernel_size=3, stride=2),
torch.nn.Conv2d(192, 192, kernel_size=3, padding=1),
torch.nn.ReLU(inplace=True),
)
self.H_out = H // (2 * 2 * 2)
self.W_out = W // (2 * 2 * 2)
# linear classifier
self.classifier = torch.nn.Sequential(
torch.nn.Dropout(),
torch.nn.Linear(192 * self.H_out * self.W_out, 2048),
torch.nn.ReLU(inplace=True),
torch.nn.Dropout(),
torch.nn.Linear(2048, 2048),
torch.nn.ReLU(inplace=True),
torch.nn.Linear(2048, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 192 * self.H_out * self.W_out)
x = self.classifier(x)
return x
For hooking this model up with the framework, you need only add three lines.
Add an
Exporterobject to the model, e.g. by passing it as a constructor parameterdef __init__(self, input_shape, exporter, num_classes=1000): # ...Inform the
Exporterof the model:exporter.set_model(self)Inform the
Exporterof which layers to track. You can pass it the entire model in which case it will track everything recursively, or pass it individual modules.exporter.add_modules(self) # alternatively, only track some layers exporter.add_modules(self.features)For convenience, the following also works
self.features = torch.nn.Sequential( exporter(torch.nn.Conv2d(C, 64, kernel_size=5, stride=2, padding=1)), torch.nn.ReLU(inplace=True), torch.nn.MaxPool2d(kernel_size=3, stride=2), exporter(torch.nn.Conv2d(64, 192, kernel_size=3, padding=2)), torch.nn.ReLU(inplace=True), torch.nn.MaxPool2d(kernel_size=3, stride=2), torch.nn.Conv2d(192, 192, kernel_size=3, padding=1), torch.nn.ReLU(inplace=True), )Add
Subscribers to the sameMessageBuswhich theExporteruses. They take certain parameters which you can look up in the documentation.# create a Subscriber which publishes the ratio between gradients # and weights (for each layer that has them) as a tensorboard scalar ratio_subscriber = RatioSubscriber(['gradients', 'weights_'], backend='tb') exporter.message_bus.register_subscriber(ratio_subscriber)
There are two optional steps
- You should call
epoch_finished()whenever you’ve run through the training set once, at least if any of yourSubscribers rely on the'epoch_finished'message or the epoch-local step counter.- You should inform the Exporter of the loss function in use by calling
set_loss(), if any of yourSubscribers need access to the input labels or the final output of the network
Details¶
Ikkuna is a Publisher-Subscriber framework, which means that in this case, a
central authority publishes data from the training process and relays it to all
registered subscribers. This central authority is the
Exporter class. Internally, it replaces some of the
Model’s methods with wrappers so it can be transparently informed of anything
interesting happening. It uses PyTorch hooks (see
torch.nn.Module.register_forward_hook() and related methods) on the
Modules it is tracking and the Tensors
inside.
Messages published from the Exporter come in two types,
the NetworkMessage for events which are not tied
to any specific module and ModuleMessage for
those that are. All messages have a kind
attribute, which is the topic the message is about. For
NetworkMessages, the following kinds are
available:
'activations', 'layer_gradients'
}
'''Message kinds which are tied to a specific module and always carry data. These topics is just
what comes with the library, others can be added to a specific :class:`MessageBus`'''
Most of these topics do not come with any data attached, but for some, the
messages data attribute will not be
None, but contain Tensors.
For ModuleMessages, the following
kinds are available:
class Message(abc.ABC):
'''Base class for messages emitted from the :class:`~ikkuna.export.Exporter`.
These topics always come with data attached and it is an error to attempt
creating a ModuleMessage without passing data.
Creating a new Subscriber¶
For adding your own metric, you must subclass
Subscriber or the more specialised
PlotSubscriber if the metric can be displayed
in a line plot. All you need to do is write an __init__ method and override
compute(). Your initializer should
contain at least the following arguments:
def __init__(self, message_bus, kinds, tag=None, subsample=1, ylims=None, backend='tb'):
Their significance is:
kinds: you’ll have to create aSubscriptionobject which represents the kind of connection to the Publishermessage_bus: Theikkuna.export.messages.MessageBusis the receiver and sender of all messages. You should pass this bus to the superclass initialiserkinds: the kinds/topics of messages to receive. For now, refer to the source code forikkuna.export.messagesfor a list of available topics.tag: a tag can be used for filtering messages. I’m not sure what this would be useful for, but theSubscriptioninstance removes messages which do not have the correct tag.
For the other args, peruse the documentation of __init__()
A Subscription object contains the
information about the topic, subsampling (maybe you want to process only every n-th
message) and tagging. Tags can be used to filter messages, but are currently
unused. A more specialised form is SynchronizedSubscription.
This subscription takes care of synchronising topics, meaning if your Subscriber
needs several kinds of messages for each module at each time step, this class
takes care of only releasing the messages in bundles after all kinds have been
received for a module.
The Subscriptions will invoke the
Subscribers
compute() method with either single
messages, if no synchronisation is used, or
MessageBundle objects which contain the data
for one module and all desired kinds. As an example, consider the
RatioSubscriber:
class RatioSubscriber(PlotSubscriber):
'''A :class:`~ikkuna.export.subscriber.Subscriber` which computes the average ratio between two
quantities. The dividend will be the first element of the
:attr:`~ikkuna.export.subscriber.Subscription.kinds` property, the divisor the second.
Therefore it is vital to pass the message kinds to the
:class:`~ikkuna.export.subscriber.Subscription` object in the correct order.'''
def __init__(self, kinds, message_bus=get_default_bus(), tag='default', subsample=1, ylims=None,
backend='tb', absolute=True):
'''
Parameters
----------
absolute : bool
Whether to use absolute ratio
'''
if len(kinds) != 2:
raise ValueError(f'RatioSubscriber requires 2 kinds, got {len(kinds)}.')
title = f'{kinds[0]}_{kinds[1]}_ratio'
ylabel = 'Ratio'
xlabel = 'Train step'
subscription = SynchronizedSubscription(self, kinds, tag=tag, subsample=subsample)
super().__init__([subscription],
message_bus,
{'title': title,
'ylabel': ylabel,
'ylims': ylims,
'xlabel': xlabel},
backend=backend)
if absolute:
self._metric_postprocess = torch.abs
else:
self._metric_postprocess = lambda x: x
self._add_publication(f'{kinds[0]}_{kinds[1]}_ratio', type='DATA')
def compute(self, message_bundle):
'''The ratio between the two kinds is computed as the ratio of L2-Norms of the two Tensors.
A :class:`~ikkuna.export.messages.ModuleMessage` with the identifier
``{kind1}_{kind2}_ratio`` is published.'''
module, module_name = message_bundle.key
dividend = message_bundle.data[message_bundle.kinds[0]]
divisor = message_bundle.data[message_bundle.kinds[1]]
scale1 = dividend.norm()
scale2 = divisor.norm()
ratio = (scale1 / scale2).item()
self._backend.add_data(module_name, ratio, message_bundle.global_step)
kind = f'{message_bundle.kinds[0]}_{message_bundle.kinds[1]}_ratio'
self.message_bus.publish_module_message(message_bundle.global_step,
As you can see, the Subscriber initialiser
takes a plot_config dictionary to pass along some information to the
visualisation backend. If your subscriber in turn publishes further messages,
you can use the _add_publication()
method to announce it to the world.
Installing the Subscriber¶
If you want your newly defined class to be accessible throughout the current
Python environment (system-wide, user, conda, virtualenv, whatever), you need to
create a new project with a setup.py file like this
#!/usr/bin/env python
from distutils.core import setup
import setuptools
setup(name='<your package name>',
version='<version>',
description='<description>',
author='<your name',
author_email='<your email>',
packages=['<package name>'],
# ... any other args
entry_points={
'ikkuna.export.subscriber': [
'YourSubscriber = module.file:YourSubscriber',
]
})
If you then run python setup.py install, you will be able to import
YourSubscriber through ikkuna.export.subscriber as if it had been
shipped with the library.